——百圖生科打造世界首個超大規模跨模態生物計算模型
摘要:本案例描述了在當下這一中國健康事業發展的最佳歷史機遇期,百圖生科如何基於全球首個大規模跨模態生物計算AI大模型,變革傳統新藥研發格局,解碼免疫系統,助力攻克免疫相關疾病。如今,隨着數據的積累和技術的進步,免疫疾病的精準診斷和治療進入一個新的歷史發展階段,中國科學院院士董晨稱之爲“免疫3.0/計算免疫學時代”。其中,AI是最值得關注的新興先進生產力之一。但是,面對生物醫藥領域的海量、分散、形式各異的數據,面對人體免疫系統的高度複雜度,究竟應該如何搭建起有效的AI工具?在這個問題上,作爲國內首家生物計算公司,百圖生科作出重要示範,打造了全球首個超大規模跨模態生物計算大模型“xTrimo”。這一大模型體系能夠表徵單體蛋白質、蛋白質相互作用、免疫細胞、免疫系統等多層次生物問題,爲開發突破創新性藥物提供強大的計算生物學能力,從而爲全球10億多患者帶來更多新的可能。
關鍵詞:生物計算;預訓練模型;百圖生科;人工智能;多模態;新藥研發;免疫疾病;蛋白質結構預測
案例正文:
在一個人的全生命週期,免疫系統是機體正常運行的“基石”。數據顯示,人類疾病的90%以上都與人體免疫系統異常相關。
但是,我們對於整個免疫系統的認知還遠遠不夠。這也就導致了,目前全球仍有超10億人不得不忍受着癌症、自身免疫性疾病、纖維化、感染性疾病、衰老等免疫相關疾病的痛苦。
雖然在應對疾病的手段上,我們已經發展出了疫苗及多種免疫調節藥物,但當前免疫調控藥物尚未實現精準靶向和調控,因此在有效性和安全性上仍有較大改進空間。
與此同時,全球的新藥研發一直面臨研發週期長、研發投入高、成功率低等亟待破解的現實問題,爲了縮短研發週期、降低成本、提高成功率,這就需要藉助人工智能(AI)、大數據等更加智慧的“工具”。正如中國工程院院士詹啓敏所表示的,近年來我國推進的前沿生物技術,其中一項就是用人工智能來預測蛋白結構、發現藥物靶點。
當整個醫藥行業對新的工具如飢似渴,當全球數億生命對新的治療手段翹首以盼,全球首個跨模態生物計算大模型“xTrimo”應運而生。
當AI“讀懂”免疫系統
從整個人體來看,免疫系統是一個由細胞、組織和器官組成的高度複雜的系統:
其中一個器官發生了問題,就會引起全身的各種各樣的複雜反應;器官內部也是一個複雜的網絡,一種器官由各種不同類型的細胞構成;而細胞中各種各樣的蛋白質、DNA、RNA,還需要通過非常複雜的相互作用協調才能完成細胞的功能;這些各種各樣的蛋白質、DNA、RNA,本身都是非常複雜的大分子,有着自己的結構和功能。
所以,無論器官、組織還是細胞尺度來看,整個免疫系統都是一個非常複雜的網絡。
幸運的是,這個複雜的網絡並非不可觀測,諸如高通量測序等實驗技術的發展,使得生物醫藥數據呈現不同尺度的“大爆炸”狀態。例如,蛋白質序列數據是以指數級增長的,它的增長速度甚至超過了芯片中計算單元的增長速度。
一方面是系統本身的高度複雜性,一方面是這種複雜性帶來的數據爆炸,對傳統的生物學或者生物信息學家來說,傳統的、小型的分析工具已愈發難以奏效。
得益於人工智能技術的發展,尤其是預訓練範式的出現,整合多尺度生物數據、解析免疫系統的複雜性成爲可能。
技術原理上,大規模預訓練模型使用自監督學習的方法,讓模型先對海量無標註數據中的規律和知識進行提煉、學習,當面向任務和場景應用時,只需要少量的任務標註數據,就能通過持續微調得到在應用場景中非常好用的模型,對具體任務的賦能效果顯著。
如今,人工智能落地已經進入“大模型”時代,美國斯坦福大學的權威研究團隊更是將這一類大規模預訓練模型形容爲“基礎模型”(Foundation Models),意味着其會是各種行業智能應用必不可少的大型基礎設施。
在NLP、CV等多類任務上,大模型已經展現出碾壓性優勢,發展生物計算大模型正當時:人體這一多尺度的複雜網絡,加上多模態、高噪音的超大規模生物數據,非常需要獨有的超大模型來提升研發效果。因此,百圖生科開發了具有千億參數的生物計算大模型體系“xTrimo”,爲開發突破創新性藥物提供強大的計算生物學能力。
“xTrimo”能夠表徵單體蛋白質、蛋白質相互作用、免疫細胞、免疫系統等多層次生物問題,理解生物數據之間關聯性,讓大量可能沒有標籤、不是針對特定問題產生的數據,轉化成一類標準,並且在訓練之後,能夠很好遷移到其他靶點和疾病上。這也正是跨模態生物計算大模型的特殊之處。
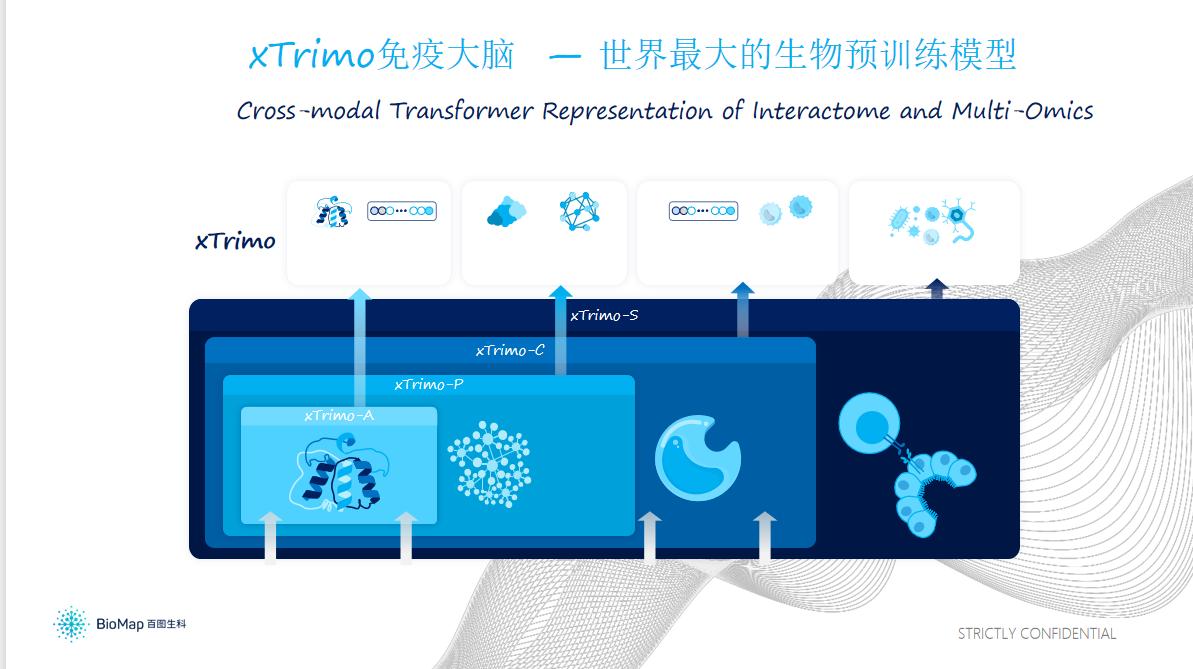
在結構上,與生物計算領域蛋白質序列、蛋白質相互作用、細胞層面、細胞系統四個不同層面的信息相對應,整個“xTrimo”體系也採用4層嵌套結構:
最內層的模型吸收蛋白質序列信息,對蛋白質的結構、性質進行預測;
第二層模型吸收蛋白質與蛋白質、蛋白質與其他分子之間相互作用的數據,進行蛋白質相互作用複合物結構預測、抗體抗原結合表位預測以及結合的親和力預測等問題;
第三層是更大尺度的細胞層面的建模,同時考慮蛋白質相互作用、蛋白質對基因表達調控的功能關係,預測細胞在擾動以及組合擾動的情況下發生的變化;
在單個細胞建模之上,最外層模型要考慮複雜的免疫系統以及免疫系統和腫瘤或其他環境的相互作用,需要引入大量細胞之間的相互通信、細胞和環境之間相互作用的數據,從而更好地預測免疫系統對擾動的響應。
使用公開的實驗數據和百圖生科的自產數據進行預訓練之後,模型可以吸收這些泛相關數據中的信息,獲得各式各樣的表徵,這種底層的表徵可以用在上層模型上作爲輸入,第二層模型輸出又可以作爲上面一層模型的輸入,讓整個體系裏的數據流通,或是讓模型之間組合在一起。最後,在細胞系統層面的模型可以和下面的蛋白質預訓練模型鏈條產生更好的效果。
實驗結果證明,即使在蛋白質結構預測這個已經被AlphaFold2充分挖掘的問題上,預訓練大模型也能帶來顯著的提升。
AI加速藥物研發
藉助“xTrimo”不斷深入揭祕和高度模擬人類整個免疫系統,科研人員現在可以在AI的指引下更系統地尋找靶點、更有針對性地進行藥物設計。
要知道,雖然當今的新藥研發早已不是“神農嘗百草”,但又陷入到“反摩爾定律”的困境之中:10億(資金成本高)、10-12年(研發週期長)、5%-10%(成功率低)。
當前主流藥物研發主要還是依託傳統生物學,根據相對有限的實驗數據或文獻報道結果,篩選可能靶點或作爲推動功能驗證的依據。
這其中的流程和鏈條非常之長,有在實驗室發現的過程,在動物身上驗證的過程,也有在真實病人身上驗證的過程,中間每個環節都有非常重要的參數需要考慮。整個實驗的流程本身就很長。後續還需要等待病人加入,臨牀試驗同樣曠日持久。
如果在醫藥研發的前期階段,讓AI模型能夠考慮到後續可能造成失敗的因素,讓諸如藥物篩選、研發出來的靶點、對應的藥物一次通過實驗,就可以更好地縮短流程,讓科研人員更快研發出新藥。如果在計算機中就能進行初期的藥物篩選,減少實驗的次數,這不但能夠把造價縮減到諸如一半的程度,也可以大大加速藥物的研發過程,讓人們用同樣的資金研發出更加多的藥物。
隨着“xTrimo”體系的發展和迭代,AI在蛋白質藥物設計上展現了巨大潛力,“反摩爾定律”這堵高牆正在被瓦解。
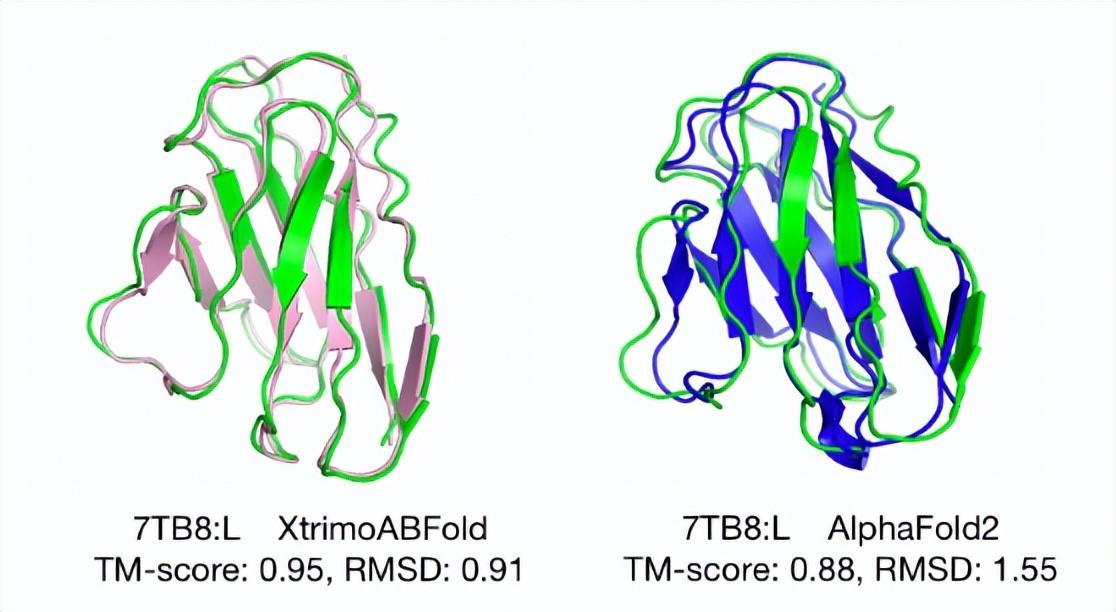
以藥物發現領域最重要的任務之一——抗體結構預測和設計爲例,抗體是免疫系統用來識別中和病原菌和病毒等異物的蛋白質,在免疫系統中發揮着重要作用。近年來,深度學習方法在蛋白質結構預測方面取得了巨大成功。尤其是AlphaFold2的出現,成爲結構生物學領域的一項重要突破。
然而,AlphaFold2的計算效率,以及其在抗體特別是抗體互補決定區域(CDR)預測的準確性還不夠理想,限制了其在工業高通量藥物設計中的應用。
2022年10月,“xTrimo”體系下的新模型xTrimoABFold ,則突破了這一限制。實驗結果顯示,xTrimoABFold 優於基於 MSA 的 AlphaFold2,執行速度比 AlphaFold2 快 151 倍,並且在抗體結構預測上的準確率顯著優於所有最新的SOTAs,成爲目前已知世界上最準確的抗體結構預測模型。
研究團隊表示,xTrimoABFold新模型對抗體結構更加精準、速度更快的預測,將對藥物研發產生實質性的重要影響。
目前,已經有一批基於“xTrimo”體系設計的創新藥物進入到後續開發階段。
展望未來,超大規模預訓練模型被認爲是AI行業的明珠,將其融入到整個醫藥研發鏈條上,必然還需要巨大的持續投入和全行業的共同努力,正如百圖生科首席AI科學家宋樂博士所言:“藥物發現問題的社會價值和行業價值極高,比起其他任務場景,更能支持大規模預訓練模型的建設投入,目前百圖生科作爲平臺型生物計算企業敢於這樣挑戰這一難題,未來一定也會有更多企業投身到這個趨勢中,最終推動生物計算大模型成爲AI界最亮的明珠”。
案例評點:
“百圖生科在做一件偉大的事業,在嘗試解碼人體複雜的免疫系統,並試圖按照這個邏輯來治病救人。我們積聚了人類最強大腦和最強的運算機器和算法,這是一個前無古人的進軍。我相信,我們一定會成功解碼免疫、解碼疾病、解碼人體。”
——中國科學院院士董晨







