摘要:本案例描述了微軟亞洲研究院聯合微軟圖靈團隊推出的最新升級的 BEiT-3 預訓練模型,如何在廣泛的視覺及視覺-語言任務上,實現當前最優的遷移性能。BEiT-3 創新的設計和出色的表現爲多模態研究打開了新思路,也預示着 AI 大一統漸露曙光。通過雲部署和雲端協作,AI 將有可能真正成爲像水和電一樣的“新基建”賦能各行各業,並進一步催生顛覆性的應用場景和商業模式。
關鍵詞:BEiT-3;多模態預訓練模型;AI大一統;微軟亞洲研究院
案例正文:
當前人工智能技術正沿着追求更高精度、挑戰複雜任務、拓展能力邊界等方向持續演進。多條技術路線齊頭並進,孕育着革命性的突破:新的深度學習優化算法不斷湧現,超大規模預訓練模型等成爲近幾年最受關注的熱點之一,強化學習、自監督學習等多元學習方式加速發展。
在早期對於 AI 和深度學習算法的探索中,科研人員都是專注於研究單模態模型,並利用單一模態數據來訓練模型。例如,基於文本數據訓練自然語言處理(NLP)模型,基於圖像數據訓練計算機視覺 (CV) 模型,使用音頻數據訓練語音模型等等。然而,在現實世界中,文本、圖像、語音、視頻等形式很多情況下都不是獨立存在的,而是以更復雜的方式融合呈現,因此在人工智能的探索中,跨模態、多模態也成了近年來業界研究的重點。
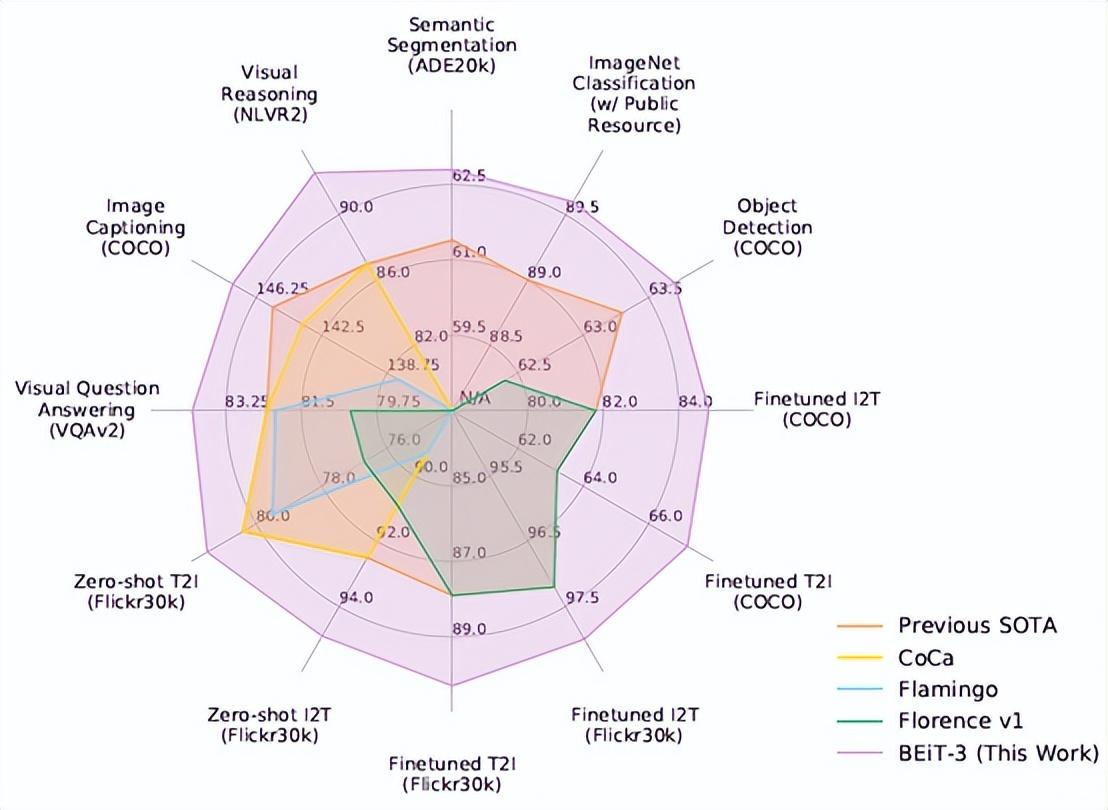
2022年,微軟亞洲研究院聯合微軟圖靈團隊推出了最新升級的 BEiT-3 預訓練模型,在廣泛的視覺及視覺-語言任務上,包括目標檢測、實例分割、語義分割、圖像分類、視覺推理、視覺問答、圖片描述生成和跨模態檢索等,實現了當前最優的遷移性能。BEiT-3 創新的設計和出色的表現爲多模態研究打開了新思路,也預示着 AI 大一統漸露曙光。
BEiT:微軟亞洲研究院爲視覺基礎大模型開創新方向
在 CV 領域的模型學習中,通常使用的是有監督預訓練,即利用有標註的數據。但隨着視覺模型的不斷擴大,標註數據難以滿足模型需求,當模型達到一定規模時,即使模型再擴大,也無法得到更好的結果,這就是所謂的數據飢餓。因此,科研人員開始使用無標註數據進行自監督學習,以此預訓練大模型參數。
以往在 CV 領域,無標註數據的自監督學習常採用對比學習。但對比學習存在一個問題,就是對圖像干擾操作過於依賴。當噪聲太簡單時,模型學習不到有用的知識;而對圖像改變過大,甚至面目全非時,模型無法進行有效學習。所以對比學習很難把握這之間的平衡,且需要大批量訓練,對顯存和工程實現要求很高。
對此,微軟亞洲研究院自然語言計算組的研究員們提出了掩碼圖像建模預訓練任務,推出了 BEiT 模型。與文本不同,圖像是連續信號,那要如何實現掩碼訓練呢?
爲了解決這一問題,研究員們將圖片轉化成了兩種表示視圖。一是,通過學習圖像“分詞器”,將圖像變成離散的符號表示,類似文本;二是,將圖像切成多個小“像素塊”,每個像素塊作爲連續表示的最小圖像輸入單元。這樣,在用 BEiT 預訓練時,模型可以隨機遮蓋圖像的部分像素塊,並將其替換爲特殊的掩碼符號[M],然後在骨幹網絡 ViT 中不斷學習、預測實際圖片的樣子。在 BEiT 預訓練後,通過在預訓練編碼上添加任務層,就可以直接微調下游任務的模型參數。在圖像分類和語義分割方面的實驗結果表明,與以前的預訓練方法相比,BEiT模型獲得了更出色的結果。同時,BEiT 對超大模型(如1B或10B)也更有幫助,特別是當標記數據不足以對大模型進行有監督預訓練時。
BEiT相關論文被 ICLR 2022 大會接收爲口頭報告論文。ICLR 大會評審委員會認爲,BEiT 爲視覺大模型預訓練的研究開創了一個全新的方向,首次將掩碼預訓練應用在了 CV 領域,非常具有創新性。

BEiT-3爲 AI 多模態基礎大模型研究打開新思路
在 BEiT 的基礎上,微軟亞洲研究院的研究員們在 BEiT-2 中進一步豐富了自監督學習的語義信息。BEiT-3 則利用一個共享的“多路Transformer(Multiway Transformer)”結構,通過在單模態和多模態數據上進行掩碼數據建模完成預訓練,並可遷移到各種視覺、視覺-語言的下游任務中。
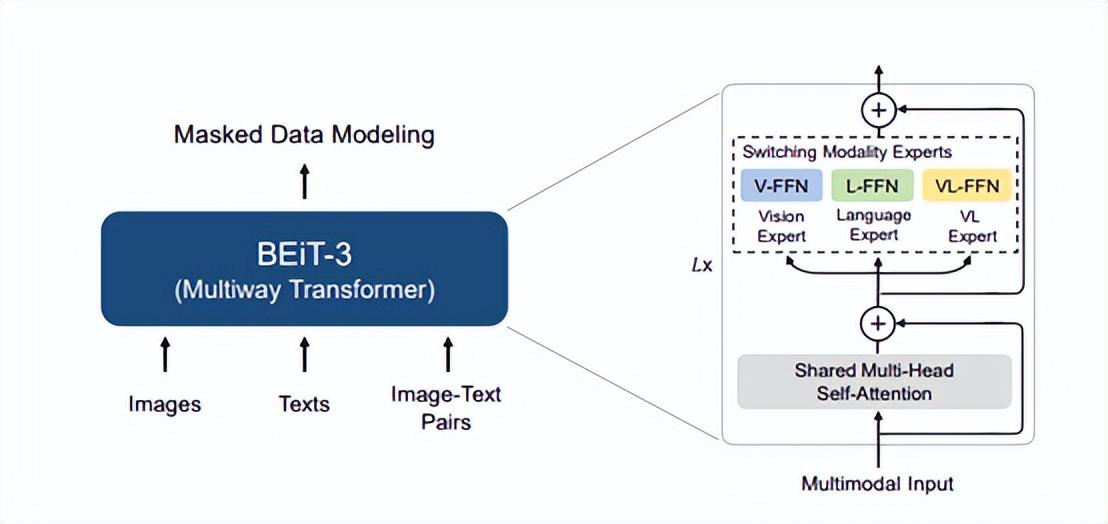
據介紹,BEiT-3 的創新之處包含三個方面:骨幹網絡、預訓練任務和擴大模型規模。
其中,在骨幹網絡方面,研究員們將多路Transformer作爲骨幹網絡以對不同模態進行編碼。每個多路Transformer由一個共享的自注意力模塊和多個模態專家組成,每個模態專家都是一個前饋神經網絡。共享自注意力模塊可以有效學習不同模態信息的對齊,並對不同模態信息深度融合編碼使其更好地應用在多模態理解任務上。根據當前輸入的模態類別,多路Transformer會選擇不同模態專家對其進行編碼以學習更多模態特定的信息。每層多路Transformer包含一個視覺專家和一個語言專家,而前三層多路Transformer擁有爲融合編碼器設計的視覺-語言專家。針對不同模態統一的骨幹網絡使得 BEiT-3 能夠廣泛地支持各種下游任務。如圖3所示,BEiT-3 可以用作各種視覺任務的骨幹網絡,包括圖像分類、目標檢測、實例分割和語義分割,還可以微調爲雙編碼器用於圖像文本檢索,以及用於多模態理解和生成任務的融合編碼器。
在預訓練任務方面,研究員們在單模態(即圖像與文本)和多模態數據(即圖像-文本對)上通過統一的掩碼-預測任務進行 BEiT-3 預訓練。預訓練期間,會隨機掩蓋一定百分比的文本字符或像素塊,模型通過被訓練恢復掩蓋的文本字符或其視覺符號,來學習不同模態的表示及不同模態間的對齊。不同於之前的視覺-語言模型通常採用多個預訓練任務,BEiT-3 僅使用一個統一的預訓練任務,這對於更大模型的訓練更加友好。由於使用生成式任務進行預訓練,BEiT-3 相對於基於對比學習的模型也不需要大批量訓練,從而緩解了 GPU 顯存佔用過大等問題。
在擴大模型規模方面,BEiT-3 由40層多路Transformer組成,模型共包含19億個參數。在預訓練數據上,BEiT-3 基於多個單模態和多模態數據進行預訓練,多模態數據從五個公開數據集中收集了大約1500萬圖像和2100萬圖像-文本對;單模態數據使用了1400萬圖像和160GB文本語料。
“BEiT 系列研究有一個一以貫之的思想和原則,就是我們認爲從通用技術層面看圖像也可視爲一種‘語言’,從而可以以統一的方式對圖像、文本和圖像-文本對進行建模和學習。如果說 BEiT 引領和推進了生成式自監督預訓練從 NLP 到 CV 的統一,那麼,BEiT-3 實現了生成式多模態預訓練的統一,”微軟亞洲研究院自然語言計算組首席研究員韋福如說。
BEiT-3 使用多路Transformer有效建模不同的視覺、視覺-語言任務,並通過統一的掩碼數據建模作爲預訓練目標,這使得 BEiT-3 成爲了通用基礎模型的重要基石。“BEiT-3 既簡單又有效,爲多模態基礎模型擴展打開了一個新方向。接下來,我們還將持續進行對 BEiT 的研究,以促進跨語言和跨模態的遷移,推動不同任務、語言和模態的大規模預訓練甚至模型的大一統。”
多模態和通用基礎模型研究還有更廣闊的空間等待探索
人的感知和智能天生就是多模態的,不會侷限在文本或圖像等單一的模態上。因此,多模態是未來一個重要的研究和應用方向。另外,由於大規模預訓練模型的進展,AI 的研究呈現出大學科趨勢,不同領域的範式、技術和模型也在趨近大一統。跨學科、跨領域的合作將更加容易和普遍,不同領域的研究進展也更容易相互推進,從而進一步促進人工智能領域的快速發展。
“尤其是通用基礎模型和通才模型等領域的研究,將讓 AI 研究迎來更加激動人心的機遇和發展。而技術和模型的統一會使得 AI 模型逐步標準化、規模化,進而爲大範圍產業化提供基礎和可能。通過雲部署和雲端協作,AI 將有可能真正成爲像水和電一樣的‘新基建’賦能各行各業,並進一步催生顛覆性的應用場景和商業模式,” 韋福如表示。







